mirror of
https://github.com/opentofu/opentofu.git
synced 2025-02-25 18:45:20 -06:00
docs: "Resource Instance Change Lifecycle" revised
The previous version of this document was produced in haste in order to support the development of the new provider framework, and so it focused only on the most important details and left some of the operations totally unmentioned. This new version aims to capture the full set of managed-resource-related provider operations, documenting when Terraform Core will call them and what the provider ought to do in order to meet Terraform Core's expectations for a valid response. This new version does still assume a certain amount of knowledge on the part of the reader about broadly what Terraform does from a user perspective and what role providers play in that process. Perhaps a future revision will include some additional background context as well, but this is a snapshot of what I had time to do today between other work and so for now I focused on presenting the remaining operations in a similar amount of detail to what was here before.
This commit is contained in:
parent
b4ff641a47
commit
543e5f4971
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 243 KiB After Width: | Height: | Size: 194 KiB |
@ -3,45 +3,94 @@
|
||||
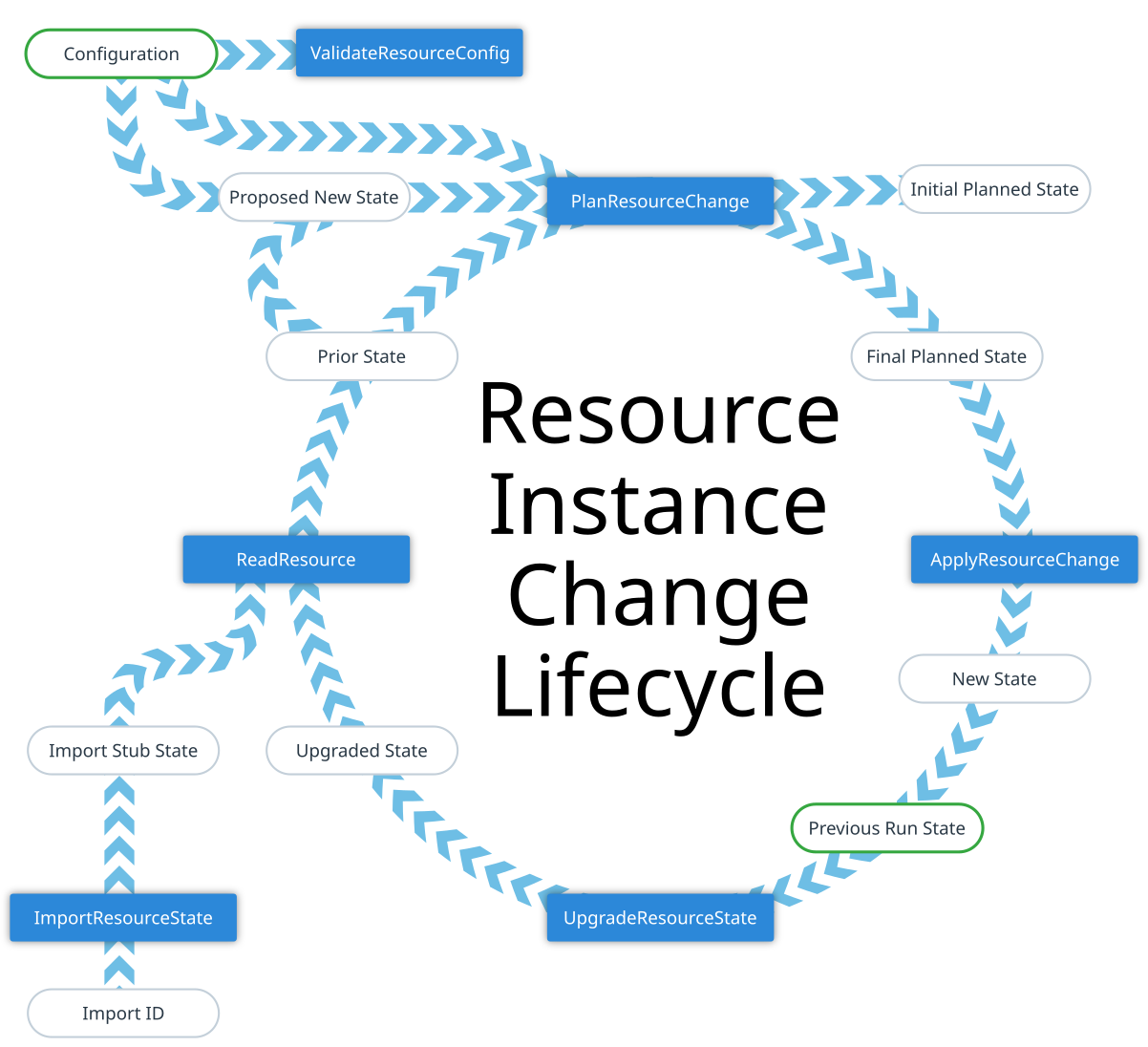
This document describes the relationships between the different operations
|
||||
called on a Terraform Provider to handle a change to a resource instance.
|
||||
|
||||

|
||||
|
||||
|
||||
The process includes several different artifacts that are all objects
|
||||
conforming to the schema of the resource type in question, representing
|
||||
different subsets of the instance for different purposes:
|
||||
The resource instance operations all both consume and produce objects that
|
||||
conform to the schema of the selected resource type.
|
||||
|
||||
* **Configuration**: Contains only values from the configuration, including
|
||||
unknown values in any case where the argument value is derived from an
|
||||
unknown result on another resource. Any attributes not set directly in the
|
||||
configuration are null.
|
||||
The overall goal of this process is to take a **Configuration** and a
|
||||
**Previous Run State**, merge them together using resource-type-specific
|
||||
planning logic to produce a **Planned State**, and then change the remote
|
||||
system to match that planned state before finally producing the **New State**
|
||||
that will be saved in order to become the **Previous Run State** for the next
|
||||
operation.
|
||||
|
||||
* **Prior State**: The full object produced by a previous apply operation, or
|
||||
null if the instance is being created for the first time.
|
||||
The various object values used in different parts of this process are:
|
||||
|
||||
* **Proposed New State**: Terraform Core merges the non-null values from
|
||||
the configuration with any computed attribute results in the prior state
|
||||
to produce a combined object that includes both, to avoid each provider
|
||||
having to re-implement that merging logic. Will be null when planning a
|
||||
delete operation.
|
||||
* **Configuration**: Represents the values the user wrote in the configuration,
|
||||
after any automatic type conversions to match the resource type schema.
|
||||
|
||||
* **Planned New State**: An approximation of the result the provider expects
|
||||
to produce when applying the requested change. This is usually derived from
|
||||
the proposed new state by inserting default attribute values in place of
|
||||
null values and overriding any computed attribute values that are expected
|
||||
to change as a result of the apply operation. May include unknown values
|
||||
for attributes whose results cannot be predicted until apply. Will be null
|
||||
when planning a delete operation.
|
||||
Any attributes not defined by the user appear as null in the configuration
|
||||
object. If an argument value is derived from an unknown result of another
|
||||
resource instance, its value in the configuration object could also be
|
||||
unknown.
|
||||
|
||||
* **New State**: The actual result of applying the change, with any unknown
|
||||
values from the planned new state replaced with final result values. This
|
||||
value will be used as the input to plan the next operation.
|
||||
* **Prior State**: The provider's representation of the current state of the
|
||||
remote object at the time of the most recent read.
|
||||
|
||||
The remaining sections describe the three provider API functions that are
|
||||
* **Proposed New State**: Terraform Core uses some built-in logic to perform
|
||||
an initial basic merger of the **Configuration** and the **Prior State**
|
||||
which a provider may use as a starting point for its planning operation.
|
||||
|
||||
The built-in logic primarily deals with the expected behavior for attributes
|
||||
marked in the schema as both "optional" _and_ "computed", which means that
|
||||
the user may either set it or may leave it unset to allow the provider
|
||||
to choose a value instead.
|
||||
|
||||
Terraform Core therefore constructs the proposed new state by taking the
|
||||
attribute value from Configuration if it is non-null, and then using the
|
||||
Prior State as a fallback otherwise, thereby helping a provider to
|
||||
preserve its previously-chosen value for the attribute where appropriate.
|
||||
|
||||
* **Initial Planned State** and **Final Planned State** are both descriptions
|
||||
of what the associated remote object ought to look like after completing
|
||||
the planned action.
|
||||
|
||||
There will often be parts of the object that the provider isn't yet able to
|
||||
predict, either because they will be decided by the remote system during
|
||||
the apply step or because they are derived from configuration values from
|
||||
other resource instances that are themselves not yet known. The provider
|
||||
must mark these by including unknown values in the state objects.
|
||||
|
||||
The distinction between the _Initial_ and _Final_ planned states is that
|
||||
the initial one is created during Terraform Core's planning phase based
|
||||
on a possibly-incomplete configuration, whereas the final one is created
|
||||
during the apply step once all of the dependencies have already been
|
||||
updated and so the configuration should then be wholly known.
|
||||
|
||||
* **New State** is a representation of the result of whatever modifications
|
||||
were made to the remote system by the provider during the apply step.
|
||||
|
||||
The new state must always be wholly known, because it represents the
|
||||
actual state of the system, rather than a hypothetical future state.
|
||||
|
||||
* **Previous Run State** is the same object as the **New State** from
|
||||
the previous run of Terraform. This is exactly what the provider most
|
||||
recently returned, and so it will not take into account any changes that
|
||||
may have been made outside of Terraform in the meantime, and it may conform
|
||||
to an earlier version of the resource type schema and therefore be
|
||||
incompatible with the _current_ schema.
|
||||
|
||||
* **Upgraded State** is derived from **Previous Run State** by using some
|
||||
provider-specified logic to upgrade the existing data to the latest schema.
|
||||
However, it still represents the remote system as it was at the end of the
|
||||
last run, and so still doesn't take into account any changes that may have
|
||||
been made outside of Terraform.
|
||||
|
||||
* The **Import ID** and **Import Stub State** are both details of the special
|
||||
process of importing pre-existing objects into a Terraform state, and so
|
||||
we'll wait to discuss those in a later section on importing.
|
||||
|
||||
|
||||
## Provider Protocol API Functions
|
||||
|
||||
The following sections describe the three provider API functions that are
|
||||
called to plan and apply a change, including the expectations Terraform Core
|
||||
enforces for each.
|
||||
|
||||
For historical reasons, the original Terraform SDK is exempt from error
|
||||
messages produced when the assumptions are violated, but violating them will
|
||||
often cause downstream errors nonetheless, because Terraform's workflow
|
||||
messages produced when certain assumptions are violated, but violating them
|
||||
will often cause downstream errors nonetheless, because Terraform's workflow
|
||||
depends on these contracts being met.
|
||||
|
||||
The following section uses the word "attribute" to refer to the named
|
||||
@ -49,47 +98,46 @@ attributes described in the resource type schema. A schema may also include
|
||||
nested blocks, which contain their _own_ set of attributes; the constraints
|
||||
apply recursively to these nested attributes too.
|
||||
|
||||
Nested blocks are a configuration-only construct and so the number of blocks
|
||||
cannot be changed on the fly during planning or during apply: each block
|
||||
represented in the configuration must have a corresponding nested object in
|
||||
the planned new state and new state, or an error will be returned.
|
||||
The following are the function names used in provider protocol version 6.
|
||||
Protocol version 5 has the same set of operations but uses some
|
||||
marginally-different names for them, because we used protocol version 6 as an
|
||||
opportunity to tidy up some names that had been awkward before.
|
||||
|
||||
If a provider wishes to report about new instances of the sub-object type
|
||||
represented by nested blocks that are created implicitly during the apply
|
||||
operation -- for example, if a compute instance gets a default network
|
||||
interface created when none are explicitly specified -- this must be done via
|
||||
separate `Computed` attributes alongside the nested blocks, which could for
|
||||
example be a list or map of objects that includes a mixture of the objects
|
||||
described by the nested blocks in the configuration and any additional objects
|
||||
created by the remote system.
|
||||
### ValidateResourceConfig
|
||||
|
||||
## ValidateResourceTypeConfig
|
||||
`ValidateResourceConfig` takes the **Configuration** object alone, and
|
||||
may return error or warning diagnostics in response to its attribute values.
|
||||
|
||||
`ValidateResourceTypeConfig` is the provider's opportunity to perform any
|
||||
custom validation of the configuration that cannot be represented in the schema
|
||||
alone.
|
||||
`ValidateResourceConfig` is the provider's opportunity to apply custom
|
||||
validation rules to the schema, allowing for constraints that could not be
|
||||
expressed via schema alone.
|
||||
|
||||
In principle the provider can require any constraint it sees fit here, though
|
||||
in practice it should avoid reporting errors when values are unknown (so that
|
||||
the operation can proceed and determine those values downstream) and if
|
||||
it intends to apply default values during `PlanResourceChange` then it must
|
||||
tolerate those attributes being null at validation time, because validation
|
||||
happens before planning.
|
||||
In principle a provider can make any rule it wants here, although in practice
|
||||
providers should typically avoid reporting errors for values that are unknown.
|
||||
Terraform Core will call this function multiple times at different phases
|
||||
of evaluation, and guarantees to _eventually_ call with a wholly-known
|
||||
configuration so that the provider will have an opportunity to belatedly catch
|
||||
problems related to values that are initially unknown during planning.
|
||||
|
||||
A provider should repeat similar validation logic at the start of
|
||||
`PlanResourceChange`, in order to catch any new
|
||||
values that have switched from unknown to known along the way during the
|
||||
overall plan/apply flow.
|
||||
If a provider intends to choose a default value for a particular
|
||||
optional+computed attribute when left as null in the configuration, the
|
||||
provider _must_ tolerate that attribute being unknown in the configuration in
|
||||
order to get an opportunity to choose the default value during the later
|
||||
plan or apply phase.
|
||||
|
||||
## PlanResourceChange
|
||||
The validation step does not produce a new object itself and so it cannot
|
||||
modify the user's supplied configuration.
|
||||
|
||||
### PlanResourceChange
|
||||
|
||||
The purpose of `PlanResourceChange` is to predict the approximate effect of
|
||||
a subsequent apply operation, allowing Terraform to render the plan for the
|
||||
user and to propagate any predictable results downstream through expressions
|
||||
in the configuration.
|
||||
user and to propagate the predictable subset of results downstream through
|
||||
expressions in the configuration.
|
||||
|
||||
The _planned new state_ returned from the provider must meet the following
|
||||
constraints:
|
||||
This operation can base its decision on any combination of **Configuration**,
|
||||
**Prior State**, and **Proposed New State**, as long as its result fits the
|
||||
following constraints:
|
||||
|
||||
* Any attribute that was non-null in the configuration must either preserve
|
||||
the exact configuration value or return the corresponding attribute value
|
||||
@ -107,44 +155,216 @@ constraints:
|
||||
changed. Set an attribute to an unknown value to indicate that its final
|
||||
result will be determined during `ApplyResourceChange`.
|
||||
|
||||
`PlanResourceChange` is actually called twice for each resource type.
|
||||
It will be called first during the planning phase before Terraform prints out
|
||||
the diff to the user for confirmation. If the user accepts the plan, then
|
||||
`PlanResourceChange` will be called _again_ during the apply phase with any
|
||||
unknown values from configuration filled in with their final results from
|
||||
upstream resources. The second planned new state is compared with the first
|
||||
and must meet the following additional constraints along with those listed
|
||||
above:
|
||||
`PlanResourceChange` is actually called twice per run for each resource type.
|
||||
|
||||
* Any attribute that had a known value in the first planned new state must
|
||||
have an identical value in the second.
|
||||
The first call is during the planning phase, before Terraform prints out a
|
||||
diff to the user for confirmation. Because no changes at all have been applied
|
||||
at that point, the given **Configuration** may contain unknown values as
|
||||
placeholders for the results of expressions that derive from unknown values
|
||||
of other resource instances. The result of this initial call is the
|
||||
**Initial Planned State**.
|
||||
|
||||
* Any attribute that had an unknown value in the first planned new state may
|
||||
either remain unknown in the second or take on any known value of the
|
||||
expected type.
|
||||
If the user accepts the plan, Terraform will call `PlanResourceChange` a
|
||||
second time during the apply step, and that call is guaranteed to have a
|
||||
wholly-known **Configuration** with any values from upstream dependencies
|
||||
taken into account already. The result of this second call is the
|
||||
**Final Planned State**.
|
||||
|
||||
It is the second planned new state that is finally provided to
|
||||
`ApplyResourceChange`, as described in the following section.
|
||||
Terraform Core compares the final with the initial planned state, enforcing
|
||||
the following additional constraints along with those listed above:
|
||||
|
||||
## ApplyResourceChange
|
||||
* Any attribute that had a known value in the **Initial Planned State** must
|
||||
have an identical value in the **Final Planned State**.
|
||||
|
||||
* Any attribute that had an unknown value in the **Initial Planned State** may
|
||||
either remain unknown in the second _or_ take on any known value that
|
||||
conforms to the unknown value's type constraint.
|
||||
|
||||
The **Final Planned State** is what passes to `ApplyResourceChange`, as
|
||||
described in the following section.
|
||||
|
||||
### ApplyResourceChange
|
||||
|
||||
The `ApplyResourceChange` function is responsible for making calls into the
|
||||
remote system to make remote objects match the planned new state. During that
|
||||
operation, it should determine final values for any attributes that were left
|
||||
unknown in the planned new state, thus producing a wholly-known _new state_
|
||||
object.
|
||||
remote system to make remote objects match the **Final Planned State**. During
|
||||
that operation, the provider should decide on final values for any attributes
|
||||
that were left unknown in the **Final Planned State**, and thus produce the
|
||||
**New State** object.
|
||||
|
||||
`ApplyResourceChange` also receives the prior state so that it can use it
|
||||
`ApplyResourceChange` also receives the **Prior State** so that it can use it
|
||||
to potentially implement more "surgical" changes to particular parts of
|
||||
the remote objects by detecting portions that are unchanged, in cases where the
|
||||
remote API supports partial-update operations.
|
||||
|
||||
The new state object returned from the provider must meet the following
|
||||
The **New State** object returned from the provider must meet the following
|
||||
constraints:
|
||||
|
||||
* Any attribute that had a known value in the planned new state must have an
|
||||
identical value in the new state.
|
||||
* Any attribute that had a known value in the **Final Planned State** must have
|
||||
an identical value in the new state. In particular, if the remote API
|
||||
returned a different serialization of the same value then the provider must
|
||||
preserve the form the user wrote in the configuration, and _must not_ return
|
||||
the normalized form produced by the provider.
|
||||
|
||||
* Any attribute that had an unknown value in the planned new state must take
|
||||
on a known value of the expected type in the new state. No unknown values
|
||||
are allowed in the new state.
|
||||
* Any attribute that had an unknown value in the **Final Planned State** must
|
||||
take on a known value whose type conforms to the type constraint of the
|
||||
unknown value. No unknown values are permitted in the **New State**.
|
||||
|
||||
After calling `ApplyResourceChange` for each resource instance in the plan,
|
||||
and dealing with any other bookkeeping to return the results to the user,
|
||||
a single Terraform run is complete. Terraform Core saves the **New State**
|
||||
in a state snapshot for the entire configuration, so it'll be preserved for
|
||||
use on the next run.
|
||||
|
||||
When the user subsequently runs Terraform again, the **New State** becomes
|
||||
the **Previous Run State** verbatim, and passes into `UpgradeResourceState`.
|
||||
|
||||
### UpgradeResourceState
|
||||
|
||||
Because the state values for a particular resource instance persist in a
|
||||
saved state snapshot from one run to the next, Terraform Core must deal with
|
||||
the possibility that the user has upgraded to a newer version of the provider
|
||||
since the last run, and that the new provider version has an incompatible
|
||||
schema for the relevant resource type.
|
||||
|
||||
Terraform Core therefore begins by calling `UpgradeResourceState` and passing
|
||||
the **Previous Run State** in a _raw_ form, which in current protocol versions
|
||||
is the raw JSON data structure as was stored in the state snapshot. Terraform
|
||||
Core doesn't have access to the previous schema versions for a provider's
|
||||
resource types, so the provider itself must handle the data decoding in this
|
||||
upgrade function.
|
||||
|
||||
The provider can then use whatever logic is appropriate to update the shape
|
||||
of the data to conform to the current schema for the resource type. Although
|
||||
Terraform Core has no way to enforce it, a provider should only change the
|
||||
shape of the data structure and should _not_ change the meaning of the data.
|
||||
In particular, it should not try to update the state data to capture any
|
||||
changes made to the corresponding remote object outside of Terraform.
|
||||
|
||||
This function then returns the **Upgraded State**, which captures the same
|
||||
information as the **Previous Run State** but does so in a way that conforms
|
||||
to the current version of the resource type schema, which therefore allows
|
||||
Terraform Core to interact with the data fully for subsequent steps.
|
||||
|
||||
### ReadResource
|
||||
|
||||
Although Terraform typically expects to have exclusive control over any remote
|
||||
object that is bound to a resource instance, in practice users may make changes
|
||||
to those objects outside of Terraform, causing Terraform's records of the
|
||||
object to become stale.
|
||||
|
||||
The `ReadResource` function asks the provider to make a best effort to detect
|
||||
any such external changes and describe them so that Terraform Core can use
|
||||
an up-to-date **Prior State** as the input to the next `PlanResourceChange`
|
||||
call.
|
||||
|
||||
This is always a best effort operation because there are various reasons why
|
||||
a provider might not be able to detect certain changes. For example:
|
||||
* Some remote objects have write-only attributes, which means that there is
|
||||
no way to determine what value is currently stored in the remote system.
|
||||
* There may be new features of the underlying API which the current provider
|
||||
version doesn't know how to ask about.
|
||||
|
||||
Terraform Core expects a provider to carefully distinguish between the
|
||||
following two situations for each attribute:
|
||||
* **Normalization**: the remote API has returned some data in a different form
|
||||
than was recorded in the **Previous Run State**, but the meaning is unchanged.
|
||||
|
||||
In this case, the provider should return the exact value from the
|
||||
**Previous Run State**, thereby preserving the value as it was written by
|
||||
the user in the configuration and thus avoiding unwanted cascading changes to
|
||||
elsewhere in the configuration.
|
||||
* **Drift**: the remote API returned data that is materially different from
|
||||
what was recorded in the **Previous Run State**, meaning that the remote
|
||||
system's behavior no longer matches what the configuration previously
|
||||
requested.
|
||||
|
||||
In this case, the provider should return the value from the remote system,
|
||||
thereby discarding the value from the **Previous Run State**. When a
|
||||
provider does this, Terraform _may_ report it to the user as a change
|
||||
made outside of Terraform, if Terraform Core determined that the detected
|
||||
change was a possible cause of another planned action for a downstream
|
||||
resource instance.
|
||||
|
||||
This operation returns the **Prior State** to use for the next call to
|
||||
`PlanResourceChange`, thus completing the circle and beginning this process
|
||||
over again.
|
||||
|
||||
## Handling of Nested Blocks in Configuration
|
||||
|
||||
Nested blocks are a configuration-only construct and so the number of blocks
|
||||
cannot be changed on the fly during planning or during apply: each block
|
||||
represented in the configuration must have a corresponding nested object in
|
||||
the planned new state and new state, or Terraform Core will raise an error.
|
||||
|
||||
If a provider wishes to report about new instances of the sub-object type
|
||||
represented by nested blocks that are created implicitly during the apply
|
||||
operation -- for example, if a compute instance gets a default network
|
||||
interface created when none are explicitly specified -- this must be done via
|
||||
separate "computed" attributes alongside the nested blocks. This could be list
|
||||
or map of objects that includes a mixture of the objects described by the
|
||||
nested blocks in the configuration and any additional objects created implicitly
|
||||
by the remote system.
|
||||
|
||||
Provider protocol version 6 introduced the new idea of structural-typed
|
||||
attributes, which are a hybrid of attribute-style syntax but nested-block-style
|
||||
interpretation. For providers that use structural-typed attributes, they must
|
||||
follow the same rules as for a nested block type of the same nesting mode.
|
||||
|
||||
## Import Behavior
|
||||
|
||||
The main resource instance change lifecycle is concerned with objects whose
|
||||
entire lifecycle is driven through Terraform, including the initial creation
|
||||
of the object.
|
||||
|
||||
As an aid to those who are adopting Terraform as a replacement for existing
|
||||
processes or software, Terraform also supports adopting pre-existing objects
|
||||
to bring them under Terraform's management without needing to recreate them
|
||||
first.
|
||||
|
||||
When using this facility, the user provides the address of the resource
|
||||
instance they wish to bind the existing object to, and a string repesentation
|
||||
of the identifier of the existing object to be imported in a syntax defined
|
||||
by the provider on a per-resource-type basis, which we'll call the
|
||||
**Import ID**.
|
||||
|
||||
The import process trades the user's **Import ID** for a special
|
||||
**Import Stub State**, which behaves as a placeholder for the
|
||||
**Previous Run State** pretending as if a previous Terraform run is what had
|
||||
created the object.
|
||||
|
||||
### ImportResourceState
|
||||
|
||||
The `ImportResourceState` operation takes the user's given **Import ID** and
|
||||
uses it to verify that the given object exists and, if so, to retrieve enough
|
||||
data about it to produce the **Import Stub State**.
|
||||
|
||||
Terraform Core will always pass the returned **Import Stub State** to the
|
||||
normal `ReadResource` operation after `ImportResourceState` returns it, so
|
||||
in practice the provider may populate only the minimal subset of attributes
|
||||
that `ReadResource` will need to do its work, letting the normal function
|
||||
deal with populating the rest of the data to match what is currently set in
|
||||
the remote system.
|
||||
|
||||
For the same reasons that `ReadResource` is only a _best effort_ at detecting
|
||||
changes outside of Terraform, a provider may not be able to fully support
|
||||
importing for all resource types. In that case, the provider developer must
|
||||
choose between the following options:
|
||||
|
||||
* Perform only a partial import: the provider may choose to leave certain
|
||||
attributes set to `null` in the **Prior State** after both
|
||||
`ImportResourceState` and the subsequent `ReadResource` have completed.
|
||||
|
||||
In this case, the user can provide the missing value in the configuration
|
||||
and thus cause the next `PlanResourceChange` to plan to update that value
|
||||
to match the configuration. The provider's `PlanResourceChange` function
|
||||
must be ready to deal with the attribute being `null` in the
|
||||
**Prior State** and handle that appropriately.
|
||||
* Return an error explaining why importing isn't possible.
|
||||
|
||||
This is a last resort because of course it will then leave the user unable
|
||||
to bring the existing object under Terraform's management. However, if a
|
||||
particular object's design doesn't suit importing then it can be a better
|
||||
user experience to be clear and honest that the user must replace the object
|
||||
as part of adopting Terraform, rather than to perform an import that will
|
||||
leave the object in a situation where Terraform cannot meaningfully manage
|
||||
it.
|
||||
|
||||
Loading…
Reference in New Issue
Block a user